Our quantitative strategy workflows run for weeks. Every day, the workflow reads portfolio state, analyzes the market, and records whether the modeled scenario changed. It has its own memory vault, signal pipeline, and research archive. It can still convince itself things are going well.
But long-running workflows drift. They get stuck in local optima where their own memory validates a failing approach. They hide behind mandate compliance while generating flat returns. They discover one signal early and never explore alternatives. The longer the workflow runs, the harder it is to notice when it has gone off course.
We needed a mechanism to periodically pull the agent back toward its objective. The naive solutions didn't work. Here's what we built instead, and why it matters for anyone running long-lived AI agents.
The Problem with Hooks
The first instinct is hooks: encoded reminders that fire during an agent's execution. Before every tool call, check some rules. If the agent is about to do something questionable, intervene.
Hooks work for simple guardrails. "Don't execute trades outside market hours." "Don't allocate more than 15% to a single position." These are pattern-matchable constraints with clear yes/no answers. We use them extensively for security and compliance.
But hooks can't answer: "Has this strategy been stock-picking disguised as quantitative analysis for the last 15 runs?" That question requires reading MLflow experiment history, cross-referencing signal ICs against position theses, checking whether model coefficients exist, and comparing stated confidence against empirical win rates across dozens of decisions. It requires judgment, not pattern matching.
Inline hooks
- Fast, but limited to pattern-matchable rules
- Can't assess trajectory across multiple runs
- No access to historical context or judgment calls
- Adding complexity makes the system fragile
Sub-agent as hook
- Can handle complex reasoning
- But blocks the main agent until completion
- Adds latency to every execution cycle
- If the sub-agent fails, the main agent stalls
You can spin off a sub-agent to handle the complex reasoning—an agent-calling-agent pattern. But now your main agent is blocked waiting for that sub-agent to finish. If the sub-agent takes ten minutes to read through MLflow, parse workspace files, and write an analysis, that's ten minutes your trading agent is frozen. If the sub-agent crashes, the main agent is stuck. You've traded one problem (limited logic) for another (brittleness and latency).
The Insight: Spaced Repetition, Not Synchronous Review
The breakthrough came from thinking about this as a reinforcement learning problem rather than a software architecture one.
An agent drifting from its objective over many runs is the same problem as a learner forgetting material over time. The solution isn't constant supervision. It's spaced repetition—periodic, asynchronous review at increasing intervals, where each review both evaluates the current trajectory and nudges the system back toward its target.
The key properties we needed:
- Non-blocking — the main trading agent should never wait for the critique to complete.
- Deep reasoning — the critique must be able to read dozens of workspace files, query MLflow, cross-reference decisions, and produce substantive analysis.
- Memory across runs — the critique must remember what it flagged before and escalate unresolved issues.
- Binding output — the critique's directives must actually constrain the agent's next decision, not just be suggestions the agent can ignore.
How We Built It: The Critique Agent in Practice
Our implementation runs inside SIQ's paper trading orchestrator. Every day, when a strategy's execution triggers fire, the orchestrator runs through a multi-phase workflow: data preparation, exploration (alpha research), and decision (portfolio construction). The critique agent inserts itself as a probabilistic pre-step before this main workflow.
Probabilistic Triggering
The critique doesn't fire on every run. It uses a probabilistic gate, similar to how spaced repetition systems increase review intervals for well-learned material:
def should_run_critique(run_count: int) -> bool:
if run_count < 10:
return False # Need sufficient decision history
return random.random() < 0.10 # ~10% of eligible runsThe first ten runs are exempt—there's not enough trajectory data to evaluate. After that, a 10% probability means a strategy running daily gets critiqued roughly every two weeks. This is deliberate: frequent enough to catch drift, rare enough to not be noise.
A Separate Agent, Same Workspace
When the critique fires, the orchestrator instantiates a completely separate QuantClaudeAgent with its own configuration. It shares the same workspace filesystem (the git worktree where the trading agent's signals, pipeline code, vault, and decisions live) but has a distinct identity:
- Its own system prompt: a senior portfolio strategist conducting an independent trajectory review
resume_sessions=False: a fresh perspective every time, no carry-over from previous critique sessions- No MCP servers: it doesn't need tool access beyond the workspace filesystem
- The trading agent's full operating instructions are passed as data, not identity—so the critique evaluates the agent against its mandate without being captured by the same reasoning patterns
What the Critique Evaluates
The critique agent reviews five dimensions, each grounded in concrete workspace evidence:
- Performance Reality Check — Is the strategy actually generating alpha? Is the agent satisfied with mediocre results? Does stated confidence match empirical win rate?
- Alpha Pipeline Health — How many distinct signal categories? Are ICs meaningful (>0.03) or noise? Does the pipeline contain hardcoded parameters?
- Mandate Compliance — Has the agent drifted from its strategy philosophy? Is it using compliance as a shield for underperformance?
- Self-Reinforcing Loops — This is the primary value-add. The agent cannot see its own loops. Seven named patterns the critique actively hunts for.
- Unexplored Dimensions — What has the agent not tried that its mandate would permit?
The Seven Loop Patterns
The self-reinforcing loop detection is where the critique earns its keep. These are the patterns an autonomous agent literally cannot diagnose in itself, because its own context window and memory reinforce the existing approach:
model.coef.* in MLflow. Positions justified by thesis, not model scores.
Structured, Binding Output
The critique produces a CritiqueDirective—a Pydantic-validated structured output with five fields:
class CritiqueDirective(BaseModel):
severity: CritiqueSeverity # "advisory" or "directive"
diagnosis: str # What's wrong, 2-3 sentences
required_actions: List[str] # Specific, session-executable actions
prohibited_patterns: List[str] # Patterns to avoid this session
evidence: str # Data backing every claimThe two severity levels have very different consequences:
- Advisory: the trading agent should consider the suggestions in its analysis.
- Directive: a hard gate. If the agent has not completed every
required_action, it is forbidden from rebalancing. It must output a HOLD decision.
This is the binding part. The directive is formatted as markdown and injected into both the exploration and decision phase prompts. In the decision phase, the orchestrator appends an explicit compliance block:
Hard Gate: "If ANY required_action is NOT completed, you MUST output decision: "hold". A REBALANCE decision that violates a DIRECTIVE-severity critique will be flagged as a compliance failure."
The agent can't just acknowledge the critique and do what it was going to do anyway. If the critique says "build a return-prediction model before rebalancing," and the agent doesn't build one, it can't trade. Period.
Cross-Run Memory
Every critique is archived to memory/critiques/critique_run_NNN.json with metadata (run count, date, strategy ID, sequence number). When the next critique fires—maybe two weeks later—the critique agent reads this archive before forming any conclusions.
This creates escalation dynamics:
- If an issue was flagged before and the agent didn't address it: "Flagged 3 runs ago, still unresolved. Escalating severity."
- If a previous directive was followed and the problem resolved: "Acknowledged improvement in signal diversity since last review."
- The critique tracks its own trajectory across reviews: is the strategy improving, stagnating, or deteriorating?
The RL Analogy
In reinforcement learning, an agent learns by receiving reward signals that push it toward optimal behavior. The reward doesn't compute the agent's next action—it just provides a gradient, a direction to adjust.
Our critique agents work the same way. They don't decide what the trading agent should do. They evaluate the trajectory, diagnose problems, and produce a nudge—a set of required actions and prohibited patterns that constrain the decision space for the next run. The trading agent still makes its own decision, but within bounds informed by an independent, asynchronous evaluation.
The objective itself is a moving target—market conditions change, the strategy evolves, new signals are discovered. A fixed set of hook rules would need constant manual updating. The critique agent adapts because it re-evaluates from first principles each time, reading the actual workspace state rather than checking against hardcoded conditions.
Results: The Agent That Listened
The screenshot below shows a real strategy execution after a critique fired. The agent's internal monologue opens with: "An Independent Performance Review was issued with severe criticism about the strategy being 'discretionary stock-picking disguised as quantitative methodology.'"
It then immediately enumerates the tasks the critique mandated:
- Initialize MLflow experiment properly
- Compute signals and log with
log_signal_run()to get actual IC values - Log model coefficients properly
- Extract lesson from a failed rotation
- Reduce concentration
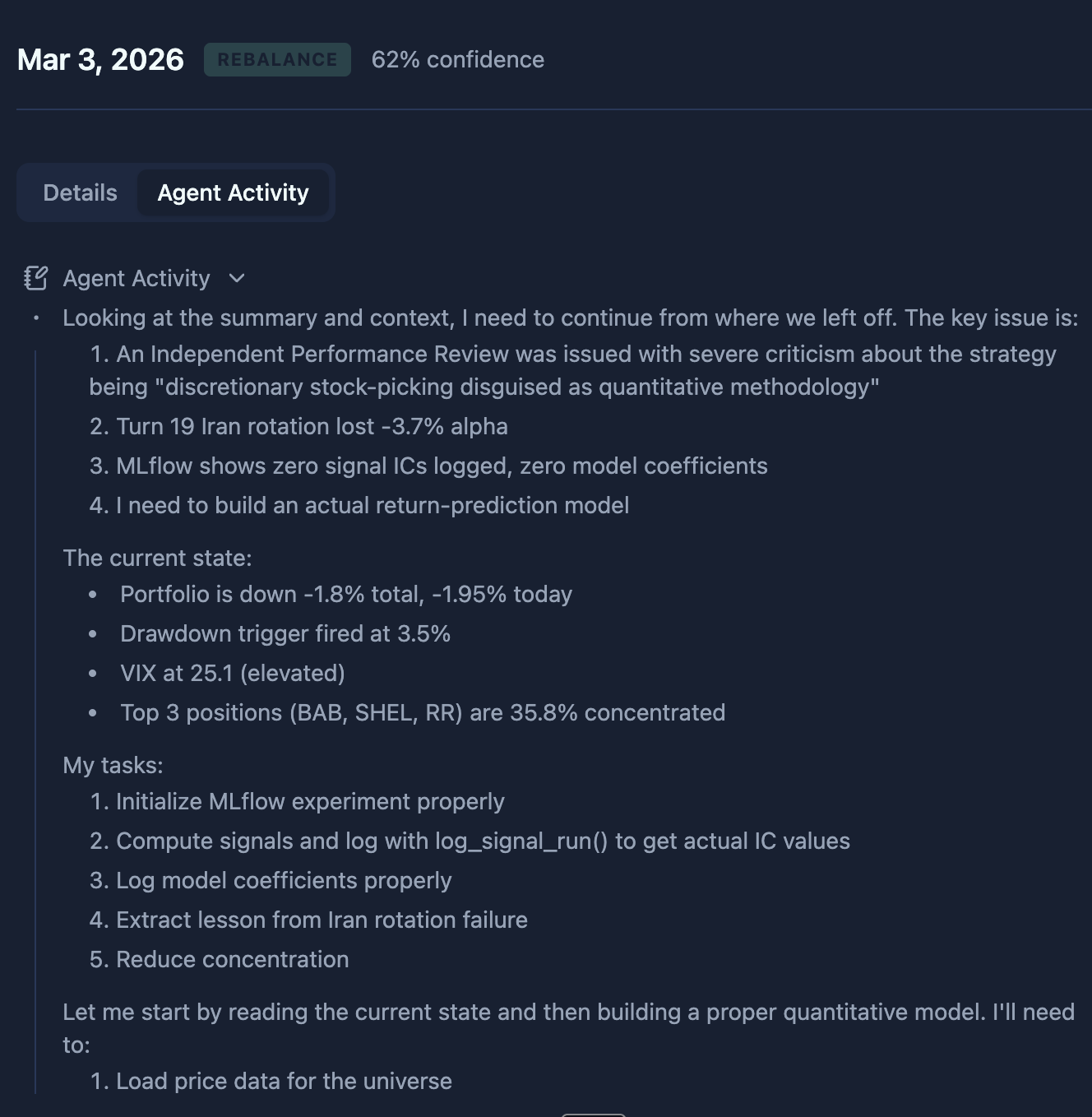
This is the behavior we wanted. The agent doesn't just mention the critique in passing—it restructures its entire execution session around addressing the required actions before making any portfolio decision. The hard gate in the decision phase ensures it can't skip this and jump to trading.
Lessons and Open Questions
What Worked
- Asynchronous execution is non-negotiable. A critique that blocked the main agent would add 10+ minutes of latency to every run it fires on. Making it a pre-step within the same orchestration cycle but a separate agent session gives us deep reasoning without blocking.
- Binding output changes behavior. Advisory-only critiques were ignored. The hard gate—HOLD if directives are incomplete—is what makes the system work. The agent can't rationalize its way past a concrete checklist.
- Cross-run memory creates accountability. Without the archive, each critique was isolated. With it, the critique agent can say "I told you this three reviews ago" and escalate. The trading agent knows its future self will be held accountable.
- The mandate-as-data pattern prevents capture. If the critique shared the trading agent's system prompt, it would inherit the same reasoning biases. Passing the mandate as data to evaluate against, rather than as identity to embody, keeps the critique independent.
What We're Still Figuring Out
- Optimal triggering probability. 10% was chosen empirically. Too frequent and it becomes noise; too rare and drift compounds between reviews. We're exploring adaptive probability based on trajectory volatility.
- Critique quality variance. Not every critique is equally useful. We built two evaluation dimensions into our testing harness—one for critique quality (did it ground every claim in evidence?) and one for critique impact (did the agent's behavior actually change?). Both must pass.
- The moving-objective problem. When the strategy itself should evolve (new market regime, new signals), the critique needs to distinguish productive evolution from problematic drift. This remains hard.
The Broader Pattern
This architecture isn't specific to trading. Any long-running AI agent that maintains state across sessions faces the same drift problem. Coding agents accumulate technical debt. Research agents get stuck in citation loops. Customer service agents develop canned response patterns.
The pattern generalizes:
- Run a separate agent with a reviewer identity, not the executor's identity.
- Give it the executor's workspace as evidence, and the executor's instructions as data to evaluate against.
- Produce structured, binding output that constrains the executor's next decision space.
- Archive the review so future reviews can escalate unresolved issues.
- Trigger probabilistically, not on every run—you want signal, not noise.
The agent doesn't need to be perfect. It needs a mechanism to notice when it's wrong. That mechanism can't be the agent itself—you need an independent perspective that shares the workspace but not the identity. You need a fresh pair of eyes on a schedule, asking the question the agent won't ask itself:
"Is this actually working, and if not, why does the agent think it is?"